

5.1.1 소트 수행과정
- 메모리 소트(In-Memory Sort) : 전체 데이터의 정렬 작업을 메모리 내에서 완료하는 것을 말하며, Internal Sort라고도 한다.
- 디스크 소트(To-Dist Sort) : 할당받은 Sort Area 내에서 정렬을 완료하지 못해 디스크 공간까지 사용하는 경우를 말하며, External Sort 라고도 한다.
5.1.2 소트 오퍼레이션
(1) Sort Aggregate
-. 전체 로우 대상으로 수행되며, 실제로 데이터를 정렬하지는 않고, 한 로우를 읽으면서 해당값을 찾는다. ex) min,max, count
(2) Sort Order by
-. 말그대로 정렬과정을 통해서 데이터를 정렬한다.
(3) Sort Group by
-. 그룹별 집계를 수행할 때 사용
-. 정렬된 그룹핑 결과를 얻고자 한다면, 실행계획에 Sort Group By라고 표시되더라도 반드시 Order By를 명시해야 한다.
(4) Sort Unique
-. Unnesting된 서브쿼리가 M쪽 집합이면 (1쪽 집합이더라도 조인 컬럼에 Unique 인덱스가 없어면), 메인 쿼리와 조인하기 전에 중복 레코드부터 제거해야한다. 이떄 Sort Unique 오퍼레이션이 발생한다.
(5) Sort join
-. 소트 머지 조인 수행 시 발생
(6) Window Sort
-. 윈도우 함수(=분석 함수) 수행 시 발생
5.2 소트가 발생하지 않도록 SQL 작성
5.2.1 Unino vs Union All
-. UNION 연상은 두 개의 테이블을 하나로 합치면서 중복된 데이터를 제거한다. 그래서 UNION은 정렬을 발생시킨다.
-. UNION ALL은 중복을 제거하거나 정렬을 유발하지 않는다. 중복제거 없이 전부 보여준다.
5.2.2 Exists 활용
-. Distinct 연산자는 조건에 해당하는 데이터를 모두 읽어서 중복을 제거해야 한다. 부분범위 처리 당여히 불가, 모든 데이터를 읽는 과정에서 많은 I/O가 발생한다.



-. Distinct, Minus 연산자를 사용한 쿼리는 대부분 Exists 서브쿼리로 변환가능한다.


5.3 인덱스를 이용한 소트 연산 생략
5.3.1 Sort Order By 생략
select 거래일시, 체결건수, 체결수량, 거래대금
from 종목거래
where 종목코드 = 'ABC'
order by 거래일시;-. 인덱스 : [종목코드 + 거래일시]
-> Order by 생략 가능
페이징처리
-. 3-Tier 환경에서 대량의 결과집합을 조회할때 페이징 처리 기법 활용
- .아래는 일반적으로 사용하는 표준 패턴
select *
from (
select rownum no, a.*
(
/* SQL BODY */
)a
where rownum <= (:page * 10)
)
where no >= (:page-1)*10 +1;
부분범위 처리 가능하도록 SQL 작성하기
select *
from
(
select 계좌번호, 거래순번, 주문금액, 주문수량, 결제구분코드, 주문매체구분코드
from 거래
where 거래일자 = :ord_dt
order by 계좌번호, 거래순번, 결제구분코드
)
where rownum <= 50
거래_pk : 거래일자 + 계좌번호 + 거래순번
거래_X01 : 계좌번호 + 거래순번 + 거래구분코드-. 거래_pk 인덱스에 결제구분코드를 추가하면 소트생략 가능
-. 실제 업무에서 PK에 컬럼을 함부로 추가 할 수 없고, 대형테이블이라면 인덱스를 최소한으로 유지해야한다.
※ 여기서 데이터 모델에 대한 이해와 집합적 사고가 필요하다.
-> PK가 [거래일자 + 계좌번호 + 거래순번]이고 거래일자 '=' 조건이다. 같은 거래일자 데이터를 [계좌번호 + 거래순번] 순으로 정렬해 놓고 보면 중복 레코드가 없다.
-> order by 절에서 결제구분코드를 제거하면 Sort Order By 오퍼레이션 사라직, 부분범위 처리 작동함
5.3.3 최소값/최대값 구하기
인덱스 이용해 최소/최대값 구하기 위한 조건
-. 조건절 컬럼과 MIN/MAX 함수 인자 컬럼이 모두 인덱스에 포함되어야함
5.3.5 Sort Group By 생략
-. region이 선두 컬럼인 인덱스를 이요하면 실행계획에 'Sort Group By Nosort' 확인가능
selecct region, avg(age), count(*)
from customer
group by region
5.4 Sort Area를 적게 사용하도록 SQL 작성
[1번]
select lpad(상품번호,30) || lpad(상품명,30) || lpad(고객ID,10) || lpad(고객명,20)
|| to_char(주문일시,'yyyymmdd hh24:mi:ss')
from 주문상품
where 주문일시 between :start and :end
order by 상품번호
[2번]
select lpad(상품번호,30) || lpad(상품명,30) || lpad(고객ID,10) || lpad(고객명,20)
|| to_char(주문일시,'yyyymmdd hh24:mi:ss')
from (
select 상품번호, 상품명, 고객ID, 고객명
from 주문상품
where 주문일시 between :start and :end
order by 상품번호
)-. 1번은 레코드당 107(=30+30+10+20+17) 바이트로 가공한 결과집합을 SortArea에 담음
-. 2번은 가공하지 않은 상태로 정렬을 완료하고나서 최정 출력할 때 가공함
-. 2번이 Sort Area를 훨씬 적게 사용함
5.4.2 Top N 쿼리의 소트 부하 경감 원리
select *
from
(
select rownum no, a.*
from
(
select 거래일시, 체결건수, 체결수량, 거래대금
from 종목거래
where 종목코드 = 'KR123456'
and 거래일시 >= '20180304'
order by 거래일시
) a
where rownum <= (:page * 10)
)
where no >= (:page-1)*10 +1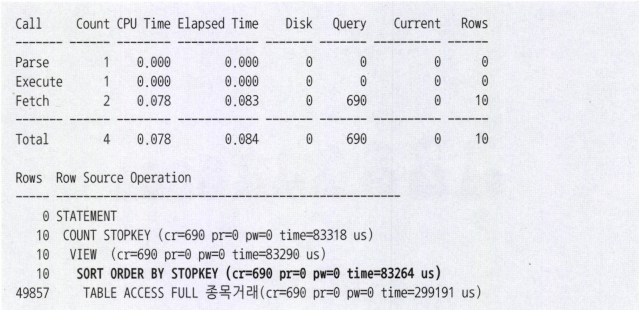
1. 종목코드가 선두컬럼인 인덱스를 사용할 수 있지만, 바로 뒤 컬럼이 거래일시가 아니면 소트연산 생략 X
2. Order by 옆에 STOPKEY를 보아 TOP N 소트 알고리즘이 동작했다.
3. page 변수에 1을 입력하면 열 개 원소를 담을 배열(Array) 공간만 있으면된다.
4. 열 개짜리 배열에 오름차순으로 정렬해서 배열에 담은다음 이후 읽은 레코드에 대해서는 배열 맨 끈에 있는 값과 비교해서 그보다 작은 값이 나타날 때만 배열을 재배치한다.

5.4.4 분석함수에서의 TOP N소트
-. rank나 row_number 함수는 max 함수보다 소트부하가 적다.
-> Top N 소트 알고리즘이 작동하기 때문이다.
'Database > SQLP' 카테고리의 다른 글
| [SQLP] 핵심노트1) 3.인덱스 튜닝_61번 (1) | 2023.10.11 |
|---|---|
| [친절한SQL 6장] 기본 DML 튜닝 (0) | 2023.02.14 |
| [친절한 SQL 4장] 조인튜닝 (0) | 2023.01.08 |
| [친절한 SQL 3장] 인덱스 튜닝 (2) | 2022.12.26 |
| [친절한 SQL 2장] 인덱스 기본 (0) | 2022.12.07 |