

※ ROWID : 오브젝트 번호, 데이터파일 번호, 블록번호
DBA : 데이터파일번호 + 블록번호
3.1.2 인덱스 클러스터링 팩터
-. 클러스터링 팩터(Clustering Factor, 이하 'CF')는 '군진성 계수', 특정 컬럼을 기준으로 같은 값을 갖는데이터가 서로 모여있는 정도를 의미한다.
-. 인덱스 ROWID로 테이블을 엑세스할 때, 오라클은 래치 획득과 해시 체인 스캔 과정을 거쳐 어렵게 찾아간 테이블 블록에 대한 포인터(메모리 주소값)를 바로 해제하지 않고 일단 유지한다. 이를 버퍼 Pinning이라고 부른다.
-. 이 상태에서 다음 인덱스 레코드를 읽었는데, 마침 직전과 같은 테이블 블록을 가르킨다. 그러면 래치 획득과 해시 체인 스캔 과정을 생략하고 바로 테이블 블록을 읽을 수 있다. 논리적인 블록 I/O 과정을 생략할 수 있다.
3.1.3 인덱스 손익분기점
-. Table Full Scan은 시퀀셜 엑세스인 반면, 인덱스 ROWID를 이용한 테이블 엑세스는 랜덤엑세스 방식이다.
-. Table Full Scan은 Multiblock I/O인 반면, 인덱스 ROWID를 이용한 테이블 엑세스는 Single Block I/O방식이다.
-. 인덱스 스캔은 논리적, 물리적 I/O횟수도 늘어나기 때문에, 보통 손익분기점이 5 ~ 20 %
3.1.4 인덱스 컬럼 추가
-. 필요한 인덱스를 추가해서 Table Random Access 횟수를 줄인다.
3.1.5 인덱스만 읽고 처리
-. 인덱스만 읽어서 처리하는 쿼리를 'Covered 쿼리'라고 부르며, 그 쿼리에 사용한 인덱스를 'Covered 인덱스'라고 부른다.
Include 인덱스
-. Oracle에는 없지만, SQL Server 2005 버전에 추가된 기능
-. 인덱스 키 외에 미리 지정한 컬럼을 리프 레벨에 함께 저장하는 기능이다.

-.수직적 탐색에는 depno 수직적 탐색에만 이용되고 수평적 탐색에는 SAL 컬럼도 필터 조건으로 사용할수 있다. SAL 컬럼은 테이블 랜덤 엑세스 횟수를 줄이는 용도로만 사용한다.
3.1.6 인덱스 구조 테이블
-. Oracle에서는 IOT(Index-Organized Table) , MS-SQL Server는 클러스터형(Clustered) 인덱스라고 한다.
-. 테이블 블록에 있어야 할 테이터를 인덱스 리프 블록에 모두 저장하고 있는 구조.
| -- 생성 구문 create table index_org_t (a number, b varchar(10) , constraint index_org_t_pk primary key (a)) organization index; -- 일반테이블을 힙 구조 테이블이라고 부르고 테이블 생성할 때 아래 organization heap 생략된다. create table index_org_t (a number, b varchar(10) , constraint index_org_t_pk primary key (a)) organization heap; |
-. IOT는 인위적으로 클러스터링 팩터를 좋게 만드는 방법 중 하나다. 같은 값을 가진 레코드들이 100% 정렬된 상태로 모여 있으므로 랜덤 엑세스가 아닌 시퀀셜 방식으로 데이터를 엑세스한다. 이 때문에 BETWEEN이나 부등호 조건으로 넓은 범위를 읽을때 유리하다.
3.1.7 클러스터 테이블
-. 인덱스 클러스터 테이블은 클러스터 키 값이 같은 레코드를 한 블록에 모아서 저장하는 구조다. 한블록에 모두 담을 수 없을 떄는 새로운 블록을 할당해서 클러스터 체인으로 연결한다.
| -- 클러스터 생성 create cluster c_dept# (deptno number(2)) index; -- 클러스터 인덱스 정의 create index c_dept#_idx on cluster c_dept#; -- 클러스터 인덱스 테이블 생성 create table dept( deptno number(2) not null , dname varchar2(14) not null , loc varchar2(13) ) cluster c_dept#(deptno); |
해시 클러스터 테이블
| -- 클러스터 생성 create cluster c_dept# (deptno number(2)) hashkeys 4; -- 클러스터 인덱스 정의 create index c_dept#_idx on cluster c_dept#; -- 클러스터 인덱스 테이블 생성 create table dept( deptno number(2) not null , dname varchar2(14) not null , loc varchar2(13) ) cluster c_dept#(deptno); |
3.2 부분범위 처리 활용
-. Paging 처리
[ORACLE] PAGING 처리
정의 데이터베이스에서 읽어와 화면에 출력할 때 한꺼번에 모든 데이터를 가져오는 것보다 출력될 페이지의 데이터만 나눠서 가져오는 것을 페이징(Paging)이라고 한다. 1. 표준 패턴 var num_page_no
origina1.tistory.com
3.3 인덱스 스캔 효율화
-. 인덱스 선행 컬럼이 조건절에 없거나 '=' 조건이 아니면 인덱스 스캔 과정에 비효율이 발생한다.
-. 선두컬럼 : 인덱스 구성상 맨 앞쪽에 있는 컬럼
-. 선행컬럼 : 어떤 컬럼보다 상대적으로 앞쪽에 놓인 컬럼
3.3.3 엑세스 조건과 필터조건
-. 인덱스 엑세스 조건 : 수직적 탐색을 통해 스캔시작점 결정에 영향을 미침
-. 인덱스 필터 조건 : 인덱스 리프 블록 스캔을 어디서 멈출지 결정하는데 영향
| ※ 옵티마이저의 비용계산 원리 비용 = 인덱스 수직적 탐색 비용 + 인덱스 수평적 탐색 비용 + 테이블 랜덤 엑세스 비용 = 인덱스 루트와 브랜치 레벨에서 읽는 블록 수 + 인덱스 리프 블록을 스캔하는 과정에 읽는 블록 수 + 테이블 엑세스 과정에 읽는 블록 수 |
3.3.4 비교 연산자 종류와 컬럼 순서에 따른 군집성
-. 첫번째 나타나는 범위 검색 조건 이후 컬럼 스캔 범위를 줄이지 못하는 경우
| 1. 좌변 컬럼을 가공한 조건절 2. 왼쪽 % 또는 양쪽 %를 사용한 like 조건절 3. 같은 컬럼에 대한 조건절이 두 개 이상일 때, 인덱스 엑세스 조건으로 선택되지 못한 조건절 4. OR Expansion 또는 INLIST ITERATOR로 선택되지 못한 OR 또는 IN 조건절 |
3.3.6 BETWEEN을 IN-List로 전환
-. 인덱스 [아파트시세코드 + 평형 + 평형타입 + 인터넷매물]

-. between을 IN-List로 고치면
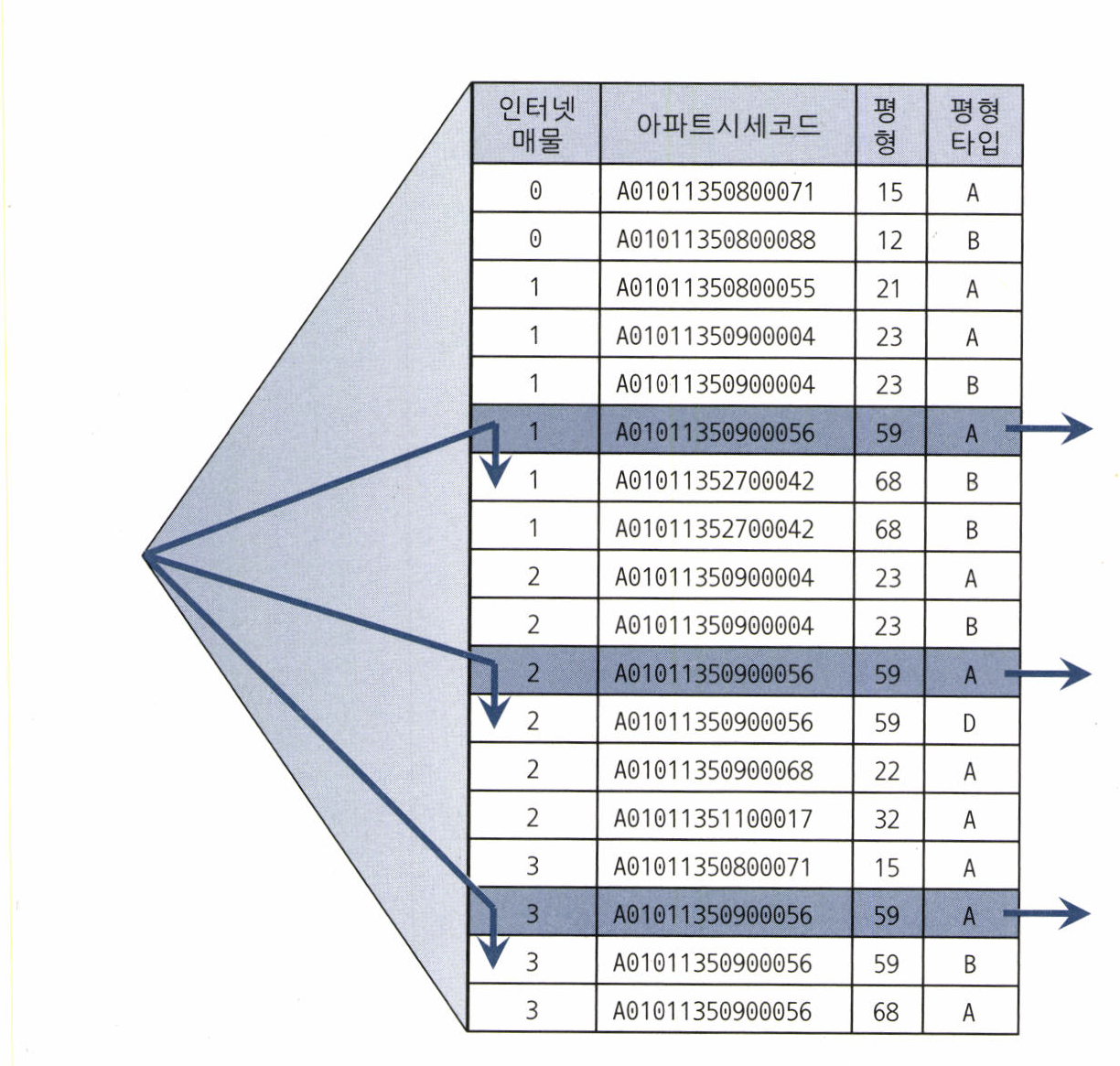


-. IN-List 항목개수가 늘어나면 위 방법이 비효율적이다.
-. 이럴땐 아래처럼 NL방식의 조인문이나 서브쿼리로 구현한다.

3.3.8 IN 조건은 '=' 인가?
-. 인덱스의 구성에 따라 성능이 달라진다.

-. 상품번호ID + 고객번호로 구성할 경우 IN-LIST Itorator방식이 효과적이다.
-. 고객번호 + 상품번호ID로 구성될 경우 IN-LIST Itorator방식이 비효율적임
NUM_INDEX_KEYS 힌트
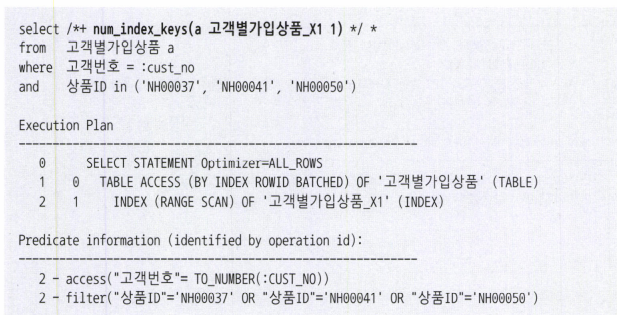
-. 2번째 인덱스 컬럼을 가공하는것도 하나의 방법이다.
3.3.9 BETWEEN 과 LIKE 스캔 범위 비교

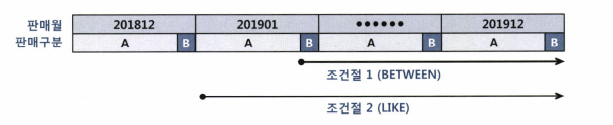
-. 조건절2는 스캔하다가 뒷 블록에 데이터 2019 단어가 포함될 수 있기때문에 스캔범위가 늘어난다.
3.3.11 다양한 옵션 조건 처리 방식의 장단점 비교
OR 조건 활용
-. 인덱스 선두 컬럼에 대한 옵션 조건에 OR 조건을 사용해선 안된다.
LIKE / BETWEEN
-. 왠만하면 정확하게 BETWEEN으로 표현하는게 좋다.
-. 숫자형이면 인덱스 조건으로도 사용가능한 컬럼에 대한 옵션 조건 처리는 LIKE 방식을 사용해선 안된다.
UNION ALL 활용

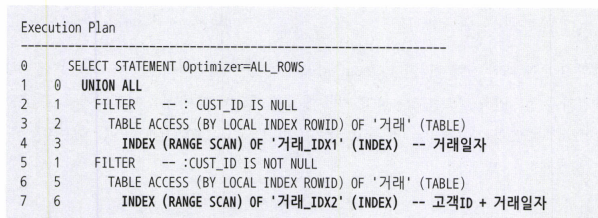
NVL/DECODE 함수활용
-. 위의 코드를
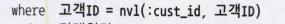

이렇게 표현해도 된다.
-. NVL / DECODE를 사용가능한 이유는 OR Expansion 쿼리 변환이 일어났기 때문인데, 만약 작동하지 않는다면 위 패턴으로 인덱스 엑세스 조건 사용이 불가능 하다.
예를 들어 :cust_id에 null값이 들어가면 어느 한 시작점을 찾을 수 없다.
-. LIKE 패턴 처럼 NULL을 허용하는 컬럼에는 사용할 수 없다.

3.3.12 함수호출부하 해소를 위한 인덱스 구성
PL/SQL 함수의 성능적 특성


느린이유 3가지
1. 가상머신 상에서 실행되는 인터프리터 언어
2. 호출 시마다 컨텍스트 스위칭 발생
3. 내장 SQL에 대한 Recursive Call 발생
-. PL/SQL로 작성한 함수와 프로시저를 컴파일하면 JAVA언어처럼 바이트코드를 생성해서 데이터 딕셔너리에 저장하며, 이를 해석할 수있는 PL/SQL 엔진만 있으면 어디서든 실행할 수 있다.
-. PL/SQL도 JAVA처럼 인터프리터 언어이기 때문에 Native코드로 완전 컴파일된 내장 함수에 비해 많이 느리다.
-. PL/SQL 함수는 매번 SQL 실행엔진과 PL/SQL 가상머신 사이에 컨텍스트 스위칭이 일어난다.
-. PL/SQL 사용자 정의 함수의 성능을 떨어뜨리는 가장 결정적인 요소는 Recursive Call이다.

#튜닝


3.4 인덱스 설계
3.4.1 인덱스 설계가 어려운이유
| 1. DML 성능저하 (-> TPS 저하) Transaction Per Second(TPS) 2. 데이터베이스 사이즈 증가(-> 디스크 공간 낭비) 3. 데이터베이스 관리 및 운영 비용 상승 |
3.4.2 가장 중요한 두가지 선택기준
| 1. 조건절에 항상 사용하거나, 자주 사용하는 컬럼을 산정한다. 2. '=' 조건으로 자주 조회하는 컬럼을 앞쪽에 둔다. |
3.4.3 스캔 효율성 이외의 판단 기준
| 1. 수행빈도 -. NL조인 에서 Outer쪽(드라이빙 집합) 에서 엑세스하는 인덱스는 스캔과정에 비효율이 있더라도 큰 문제가 아닐 수 있지만 Inner쪽 스캔과정에서 비효율이 있다면 이는 성느에 큰 문제를 야기할 수 있다. -. Inner 쪽 인덱스는 '=' 조건 컬럼에 선두를 두는것이 중요, 될 수 있으면 테이블 엑세스 없이 인덱스에서 필터링을 마치도록 구성해야한다. 2. 업무상 중요도 3. 클러스터링 팩터 4. 데이터량 5. DML부하(=기존 인덱스 개수, 초당 DML발생량, 자주 갱신하는 컬럼 포함 여부 등) 6. 저장공간 7. 인덱스 관리 비용 등 |
3.4.4 공식을 초월한 전략적 설계
-. 데이터 조회량과 범위를 고려하여 , '=' 을 만족하는 컬럼을 선두에두는 컬럼을 인덱스를 구성하는것이 아닌, between 조건으로 컬럼을 필터링하는 컬럼을 선두로두는 인덱스를 두기도한다.
3.4.5 소트 연산을 생략하기 위한 컬럼 추가
| 1. '=' 연산자로 사용한 조건절 컬럼 선정 2. ORDER BY 절에 기술한 컬럼 추가 3. '=' 연산자가 아닌 조건절 컬럼은 데이터 분포를 고려해 추가 여부 결정 |
3.4.6 결합 인덱스 선택도
-. Selectivity : 1/NDV(데이터가 골고루 분포되어 있다면?), 카디널리티 / 총 레코드 수 -> 전체 레코드 중에서 조건절에 의해 선택될 것으로 예상되는 레코드의 비율
-. Cadinality : 총로우수 * 선택도(1/NDV)
-. NDV(Number of Distinct Value) : 특정 컬럼에 Unique한 값이 얼마나 있는지
-. Density : 1/NDV
-.결론적으로 인덱스 생성 여부를 셜정할 떄는 선택도가 매우 중요하지만, 컬럼 간 순서를 결정할 떄는 각 컬럼의 선택도보다 필수 조건 여부, 연산자 형태가 더 중요한 판단 기준이다. 어느 컬럼을 앞에 두는 것이 유리한지는 상황에 따라 판단할 일이다.
'Database > SQLP' 카테고리의 다른 글
| [친절한SQL 6장] 기본 DML 튜닝 (0) | 2023.02.14 |
|---|---|
| [친절한 SQL 5장] 소트 튜닝 (0) | 2023.01.19 |
| [친절한 SQL 4장] 조인튜닝 (0) | 2023.01.08 |
| [친절한 SQL 2장] 인덱스 기본 (0) | 2022.12.07 |
| [친절한 SQL 1장] SQL 처리 과정과 I/O (0) | 2022.12.05 |