

반응형
1. 동시성 제어(Concurrency Control)
※ 요약
-. 비관적 동시성제어 = 데이터를 읽는 시점에 lock을건다
-. 낙관적 동시성제어 = 데이터를 읽는 시점에 lock을 걸지 않지만 다른사용자에 의해 값이 변경됐는지 반드시 검사해야함
-. 다중버전 동시성제어 = lock 을사용하지않고 undo를 이용한 방법
[ 1.1 동시성 제어(Concurrency Control)이란? ]
동시성 제어란 DBMS가 다수의 사용자 사이에서 동시에 작용하는 다중 트랜잭션의 상호간섭 작용에서 Database를 보호하는 것을 의미한다. 일반적으로 동시성을 허용하면 일관성이 낮아지게 되며 이를 그래프로 나타내면 아래와 같다.
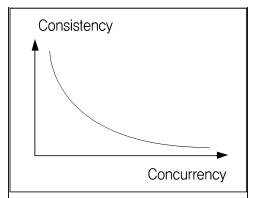
다수 사용자의 동시 접속을 위해 DBMS는 동시성 제어를 할 수 있도록 Lock 기능과 SET TRANSACTION 명령어를 이용해 트랜잭션의 격리성 수준을 조정할 수 있는 기능도 제공한다. 이렇게 동시성을 제어하는 방법에는 비관적 동시성 제어와 낙관적 동시성 제어가 있다.
[ 1.2 비관적 동시성 제어(Pessimistic Concurrency Control) ]
-
사용자들이 같은 데이터를 동시에 수정할 것이라고 가정
-
데이터를 읽는 시점에 Lock을 걸고, 트랜잭션이 완료될 때까지 이를 유지
-
SELECT 시점에 Lock을 거는 비관적 동시성 제어는 시스템의 동시성을 심각하게 떨어뜨릴 수 있어서 wait 또는 nowait 옵션과 함께 사용해야 함
[ 낙관적 동시성 제어(Optimistic Concurrency Control) ]
-
사용자들이 같은 데이터를 동시에 수정하지 않을 것이라고 가정
-
데이터를 읽는 시점에 Lock을 걸지 않는 대신 수정 시점에 값이 변경됐는지를 반드시 검사
동시성 제어의 목표는 동시에 실행되는 트랜잭션 수를 최대화 하면서 입력, 수정, 삭제, 검색 시 데이터의 무결성을 유지하는데 있다. 하지만 읽기 작업에 공유 Lock을 사용하는 일반적인 Locking 메커니즘은 구현이 간단한 반면에 아래와 같은 문제점을 가지고 있다.
[ Locking 메커니즘의 문제점 ]
-
읽기 작업과 쓰기 작업이 서로 방해를 일으키기 때문에 동시성 문제가 발생
-
데이터 일관성에 문제가 생기는 경우도 있어서 Lock을 더 오래 유지하거나 테이블 레벨의 Lock을 사용해야 하고, 동시성 저하가 발생
이러한 문제점들을 해결하기 위해 MVCC라는(Multi-Version Concurrency Control, 다중 버전 동시성 제어) 메커니즘이 탄생하게 되었다.
2. MVCC(Multi-Version Concurrency Control, 다중 버전 동시성 제어)
[ MVCC(Multi-Version Concurrency Control) 이란? ]
MVCC는 동시 접근을 허용하는 데이터베이스에서 동시성을 제어하기 위해 사용하는 방법 중 하나이다. MVCC 모델에서 데이터에 접근하는 사용자는 접근한 시점에서 데이터베이스의 Snapshot을 읽는다. 이 snapshot 데이터에 대한 변경이 완료될 때 (트랜잭션이 commit 될 때) 까지 만들어진 변경사항은 다른 데이터베이스 사용자가 볼 수 없다. 이제 사용자가 데이터를 업데이트하면 이전의 데이터를 덮어 씌우는게 아니라 새로운 버전의 데이터를 UNDO 영역에 생성한다. 대신 이전 버전의 데이터와 비교해서 변경된 내용을 기록한다. 이렇게 해서 하나의 데이터에 대해 여러 버전의 데이터가 존재하게 되고, 사용자는 마지막 버전의 데이터를 읽게 된다. 이러한 구조를 지닌 MVCC의 특징을 정리하면 아래와 같다.
-
일반적인 RDBMS보다 매우 빠르게 작동
-
사용하지 않는 데이터가 계속 쌓이게 되므로 데이터를 정리하는 시스템이 필요
-
데이터 버전이 충돌하면 애플리케이션 영역에서 이러한 문제를 해결해야 함
MVCC의 접근 방식은 잠금을 필요로 하지 않기 때문에 일반적인 RDBMS보다 매우 빠르게 작동한다. 또한 데이터를 읽기 시작할 때, 다른 사람이 그 데이터를 삭제하거나 수정하더라도 영향을 받지 않고 데이터를 사용할 수 있다. 대신 사용하지 않는 데이터가 계속 쌓이게 되므로 데이터를 정리하는 시스템이 필요하다. MVCC 모델은 하나의 데이터에 대한 여러 버전의 데이터를 허용하기 때문에 데이터 버전이 충돌될 수 있으므로 애플리케이션 영역에서 이러한 문제를 해결해야 한다. 또한 UNDO 블록 I/O, CR Copy 생성, CR 블록 캐싱 같은 부가적인 작업의 오버헤드 발생한다. 이러한 구조의 MVCC는 문장수준과 트랜잭션 수준의 읽기 일관성이 존재한다.
MVCC 는 MultiVersion Concurrency Control의 약자로 DBMS에서 Lock을 사용하지 않고, 데이터의 읽기 일관성을 보장해주는 내부 기법이다. DB는 Lock을 기본으로 하여 데이터 파일에 작성된 데이터의 일관성을 보장하는 것을 기본으로 하지만, 이것은 쓰기가 발생하는 경우에는 대기에 빠지게 하기 때문에, 쓰기가 많이 발생하는 서버에서의 동시성을 크게 떨어뜨린다.
MVCC란 Write 세션이 Read 세션을 블로킹하지 않고 그 반대로 Read세션이 Write세션을 블로킹하지 않고 서로 다은 세션이 동일한 데이터에 접근했을 때 각 세션마다 다른 버전의 문서(스냅샷 이미지)를 보장해주는 메커니즘을 의미한다.
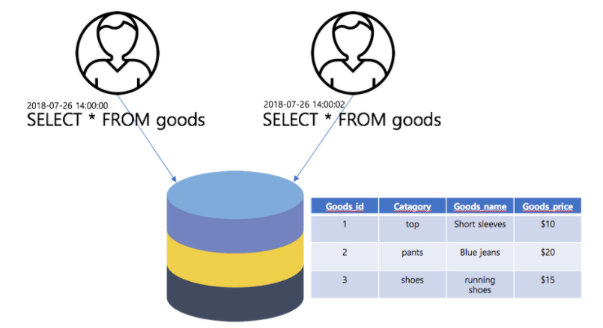
|
상황 1. 상품 전체 조회
|
상황 2. 관리자 1 청바지가격 업데이트
|
|
관리자 1이 Blue jeans 상품의 가격을 $15로 업데이트하고 트랜잭선을 완료했다.
 |
관리자 2가 Blue jeans 상품의 가격을 $25로 업데이트하고 트랜잭션을 완료하기를 시도한다.
 |
상황 3. 관리자2 청바지가격 업데이트
이때, 데이터베이스는 관리자 1과 2에 대해 다른 버전의 문서(스냅샷)을 가지고 있기 때문에 서로 독립적으로 트랜잭션을 완료할 수 있다.
하지만, 데이터베이스는 누가 먼저 똑같은 작업에 대해 UPDATE를 시도하고 수정했는지 알고 있어 가장 최근에 UPDATE를 시도한 사용자(관리자2)는 해당 부분을 다시 읽어 충돌이 발생한 지점을 해결하면 된다.(관리자2 의 작업이 더 나중에 일어난 것을 알고 유저에게 충돌이 발생해서 수정할수 없다라는 메세지를 출력한다. 그래서 그 부분을 다시 읽고 수정하면 된다. ) ?? 이부분이 무슨 말인가.... lock 이랑 차이점이 뭔가? MVCC 의 기술중에 한개인 Pessimistic lock와 undo 를 이용한게 있다. undo영역에 저장된 정보를 이용해 쿼리 시작 시점의 일관성있는 버전을 생성하고 그것을 읽는 방법
|
Isolation (Tibero)
트랜잭션은 혼자만 돌고 있는 것처럼 보이게 된다. 물론 다른 트랜잭션이 수정한 데이터에 접근할 때는 이를 기다릴 수는 있지만 다른 트랜잭션이 수정 중이므로 접근할 수 없다고 에러가 나지는 않는다. 이를 위해 Tibero에서는 Multi version concurrency control 기법과 row-level locking 기법을 사용한다.
데이터를 참조하는 경우에는 MVCC 기법을 이용하여 다른 트랜잭션과 무관하게 참조 가능하며, 데이터를 수정할 때도 row level의 fine-grained lock control을 통하여 최소한의 충돌만을 일으키고 같은 데이터에 접근한다고 해도 단지 기다림으로써 이를 해결한다.
|
이처럼 사용자는 데이터베이스에서 상품에 대한 정보를 가져오고 수정할 때, 하나의 테이블에 읽고 쓰는것 처럼 느끼지만 MVCC 메커니즘은 앞에서 설명한 방식으로 각각의 사용자에게 서로 다른 버전의 문서(스냅샷 이미지)를 제공해 충돌을 최소화 할 수 있게 해준다.
물론 동시성 제어를 위해 MVCC 말고 몇가지 방식이 있다. 대체적으로 구현이 간단한 락(Lock)을 많이 쓰이고 있지만 락(Lock)을 사용할 경우, 하나의 데이터에 대해서 위와 같은 동작을 진행할 때, 한명(관리자1)은 쓰고 다른 한명(관리자2)은 먼저 쓰기 동작을 한 사람(관리자1)이 쓰기를 완료할 때까지 대기해야하는 현상이 발생해 느리다는 단점을 가지고 있다.
반응형
'Database' 카테고리의 다른 글
| [DATABSE] DB버전 별 OS 지원 범위 (0) | 2023.09.26 |
|---|